As part of our ongoing experiments in visualization, I recently rebuilt a personal website using Omeka (or more specifically what they’re now calling “Omeka Classic”), a lightweight web publishing platform for digital collections from George Mason University’s Roy Rosenzweig Center for History and New Media. Previous exposure suggested that, by itself, it could make a decent digital asset management add-on to an existing site due to its metadata support. In this instance I wanted to discover the benefits Omeka offers when treating our corpus of plain text files as an online collection.
As it happens, there are a number of very nice plugins extending the functionality of Omeka, and several are specifically designed for text analysis and visualization. With the file content attached as an item type metadata (in this case the textual component), I was able to use the Ngram plugin to analyze term frequency and plot it over time.
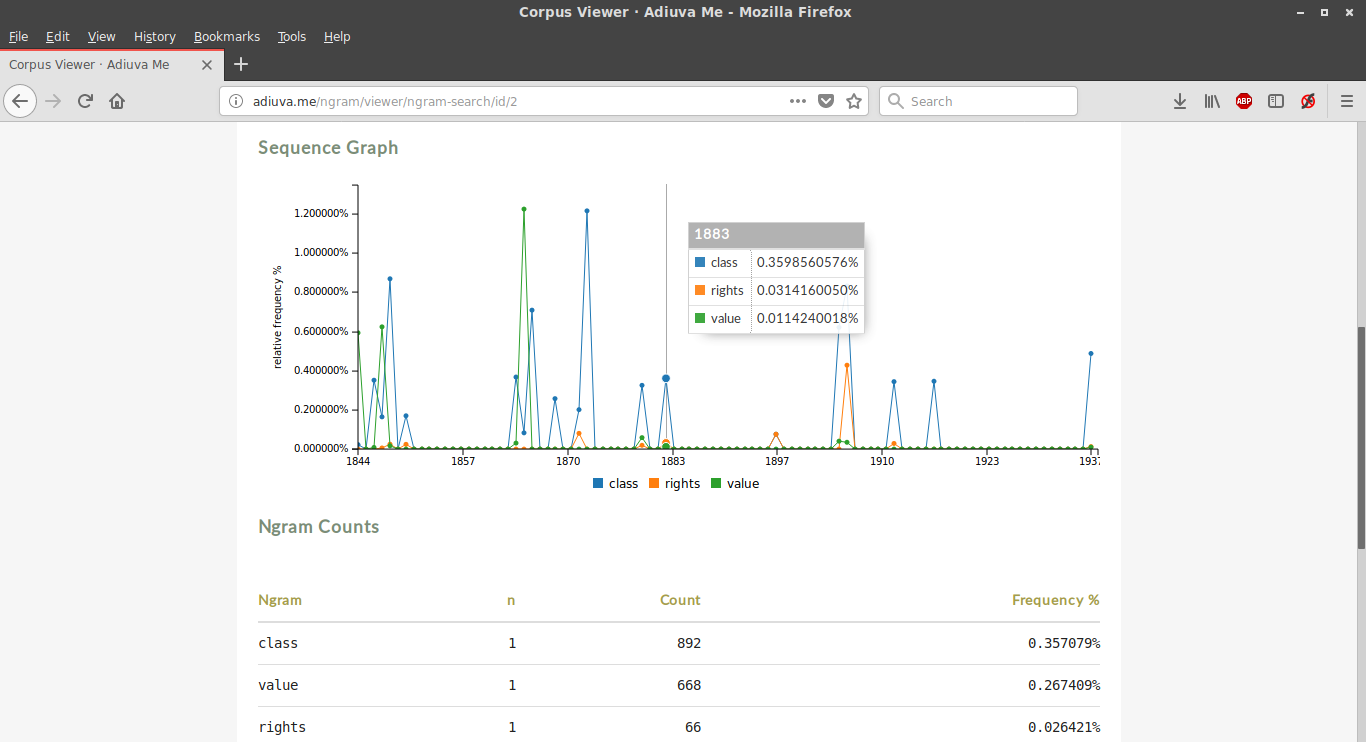
Incorporating time was necessary in order to generate a graph with a horizontal axis, and to satisfy that requirement I used the “date created” metadata field. Unfortunately this resulted in each year representing a different text, since they were largely published a year or more apart. It’s possible to generate an Ngram corpus without a date range, but for visualization purposes frequency over time is more interesting.
Another drawback to the plugin was the inability to remove stopwords, such as “a,” “the,” and “and.” However, if you search the collection using your own comma separated lists of keywords, as unigrams (single words), bigrams (two adjacent terms) or trigrams (three word combinations), the results are much more interesting.
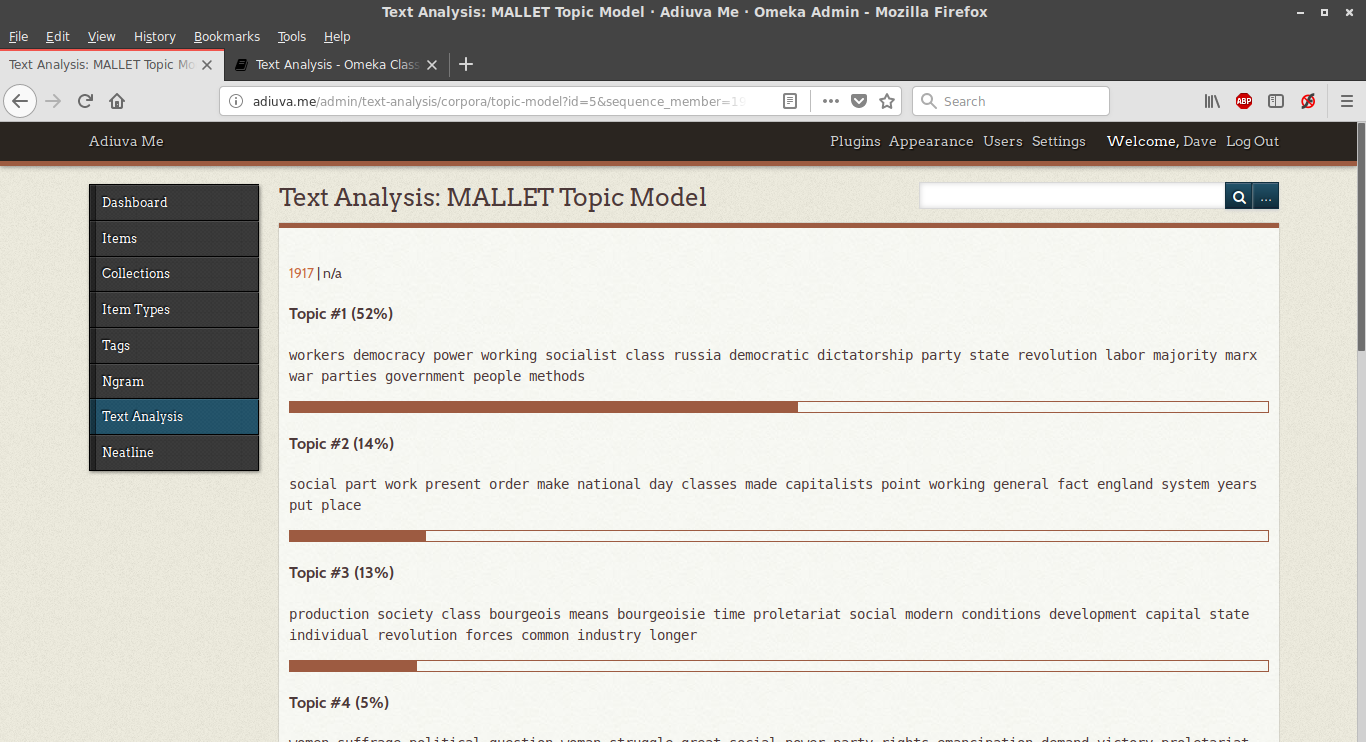
The Ngram corpus was necessary for using the aptly-named Text Analysis plugin. Taking the generated concordance, it provided a list of top-ten topic models generated by a local instance of MALLET, one for each document (a.k.a. each “year”):
Another option provided by the plugin was querying the interface of IBM’s Watson Natural Language Understanding service, offering a list of identified entities (people, places, and things), keyword sentiment analysis, and high-level concepts sorted by relevance.
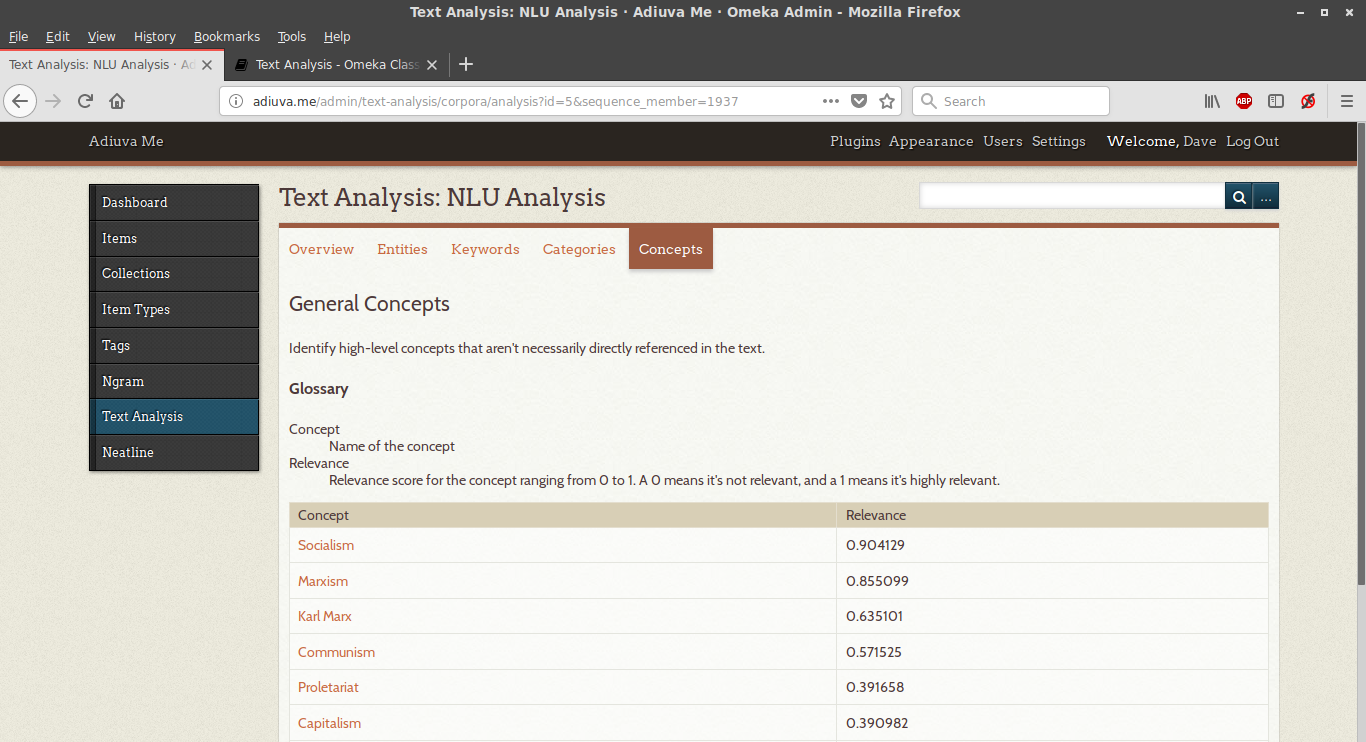
If there’s a drawback to this plugin, it’s that the results aren’t accessible to site visitors: only logged in users can see and generate analytic tables, probably due to the fact that the IBM service isn’t free beyond minimal usage.
Finally, one of the more visually appealing plugins is Neatline, a framework for creating interactive exhibits using maps and MIT SIMILE project-style timelines. Although a bit labor-intensive, as it relied on manually reproducing some of the metadata within its interface, the results were not so much interpretive as illustrative, displaying how items in the corpus related to each over space and time.
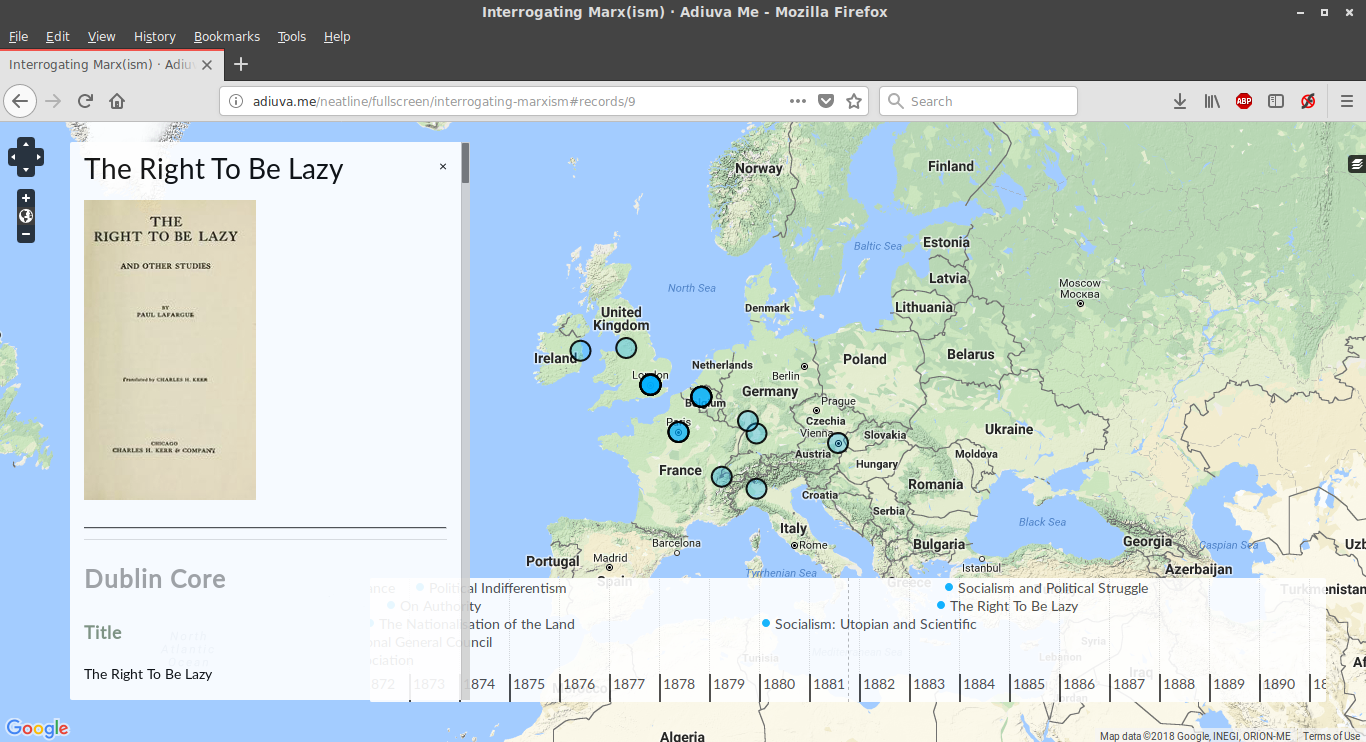
For those interested in examining these features directly, the site is http://adiuva.me/, with the Ngram corpus viewer accessible at http://adiuva.me/ngram/corpora/show/id/2 and the Neatline map at http://adiuva.me/neatline/show/interrogating-marxism. Please let us know what you think!
Really Informative Content, Thanks for sharing this!
Pingback: Learn Forget Backlink 1 – Scholarship
Neatline is another important plugin.
when i read this article, i felt something interesting, maybe i will share this to others too.
Registration here is really fast and easy. No need to be complicated, you can immediately start exploring many exciting gacor slot games. The platform is also easy to navigate
Thanks for this information from rajabandot
unsurtoto Don’t rush flashy offers; assess each platform’s trustworthiness first.
The Legendary Envoy Armor is one of the most visually striking sets in GW2, but acquiring it can be a tedious process. When you buy Gw2 Legendary Envoy Armor Boosting, you’re unlocking not only an iconic look but also a seamless experience. Let the pros take care of the hard work while you enjoy the rewards.
Thanks for this good article, by the way my name is 19DEWA
For many NBA 2K26 enthusiasts, improving player stats and achieving maximum potential is an essential part of the game. When you decide to buy NBA 2K26 lifetime boosting, you are essentially investing in an optimized gameplay experience. This boost ensures that your character has all the necessary upgrades, from increased stats to enhanced skills, which allow for more competitive play in online matches. It not only saves time but also boosts confidence as players can engage with top-tier competition without feeling underpowered.
Toto togel merupakan permainan judi tebak angka yang terdiri dari berbagai jenis taruhan berdasarkan jumlah digit angka yang dipilih. Pemain akan memilih angka-angka tertentu yang mereka anggap akan keluar pada pengundian yang dilakukan secara acak. Permainan ini dikenal dengan istilah Toto Gelap karena hasil pengundiannya tidak diketahui sebelumnya, menjadikannya sebuah permainan yang mengandalkan keberuntungan. Di Indonesia, permainan togel dimainkan dalam berbagai jenis taruhan, mulai dari 2D (dua digit), 3D (tiga digit), hingga 4D (empat digit), dengan masing-masing memiliki cara bermain dan peluang kemenangan yang berbeda.
In addition, choosing to buy GW2 Visions of Eternity mastery rank boosting is safe and reliable if you choose the right providers. Many services offer secure and professional boosting options that ensure your account remains in good hands. Whether you want to complete a particular mastery track or unlock some of the coolest rewards, boosting is a great option to save you time. This way, you can focus on the fun aspects of Guild Wars 2 and leave the grinding to the pros.
Looking for a way to level up your Black Desert Online (BDO) experience without all the grind? You can always choose to buy BDO Grinding and Farm service to skip the repetitive tasks and jump straight into the fun! Whether you’re struggling with a tough boss, need to gather resources efficiently, or want to quickly boost your gear, this service can save you a lot of time and frustration. It’s a fantastic option for players who want to progress without spending hours grinding on end. Just imagine spending more time enjoying the game and less time doing the same repetitive tasks over and over!
Olxtoto merupakan platform toto online yang menawarkan berbagai jenis permainan judi seperti togel, slot, hingga permainan kasino lainnya. Dengan berbagai pilihan permainan yang ada, Olxtoto menjadi pilihan utama bagi para pecinta judi online di Indonesia. Keunggulan dari Olxtoto terletak pada keamanan dan kemudahan akses yang mereka tawarkan kepada para pemain, serta bonus yang sering kali menjadi daya tarik utama bagi pengguna baru dan pemain setia. Selain itu, Olxtoto juga memberikan pengalaman yang sangat interaktif dan mudah dipahami oleh pemain dari segala usia. Di platform ini, Anda bisa dengan mudah memilih jenis permainan yang sesuai dengan keinginan dan tingkat kenyamanan Anda, serta memanfaatkan berbagai bonus spesial yang ditawarkan.
Keberadaan RNG (Random Number Generator) pada permainan slot sangat penting untuk memastikan bahwa hasil permainan tidak dapat dimanipulasi oleh pihak ketiga. Situs slot yang terpercaya akan mempublikasikan hasil audit dari pihak ketiga, seperti eCOGRA atau lembaga lainnya yang menjamin keadilan permainan. Pastikan untuk memeriksa apakah situs slot tersebut memiliki audit RNG yang terjamin dan dapat dipertanggungjawabkan.
Menggunakan jasa basmi rayap yang sudah berpengalaman memiliki banyak keuntungan. Salah satunya adalah adanya metode yang lebih tepat dalam menangani serangan rayap, berdasarkan pada jenis rayap yang menyerang dan tingkat kerusakan yang terjadi. Penyedia jasa yang profesional umumnya melakukan pengecekan menyeluruh di setiap bagian rumah, baik di area yang terlihat maupun yang tersembunyi. Dengan menggunakan jasa basmi rayap yang berpengalaman, pemilik rumah tidak perlu khawatir tentang kualitas dan efektivitas pengendalian rayap yang diterapkan. Selain itu, jasa yang berkompeten akan menggunakan teknologi dan produk terbaru yang ramah lingkungan, sehingga pengendalian rayap dapat dilakukan tanpa merusak struktur bangunan atau membahayakan penghuni rumah.
By choosing to buy NBA Lifetime boosting, you’re not just improving your player’s stats, but you’re also ensuring that your progress is secured over the long term. This means you won’t have to worry about constantly upgrading or purchasing boosts every season. The lifetime boost ensures that you’re always at the top of your game, no matter what new updates or challenges come your way. With a single purchase, you’ll have a powerful player that’s always ready for competitive play. It’s the ultimate convenience for those who want to play without limits.
T0812 Login
B0878 Daftar
B0878 Link
LINK LOGIN T0812 Login
Sangat informatif seperti slot
Classic slots are the original slot machines brought into the digital world. These games usually feature three reels and a limited number of paylines, often with classic symbols such as fruits, bells, and sevens. They are perfect for players who appreciate a nostalgic, simple slot experience with straightforward gameplay.
Woooo ,such a great article
If you happen to be visiting the website slot, please share your thoughts and tell us what you want to know about, or know more about, Marxism.
Thaks for this information buy gw2 gift of battle
The sunset on the beach was so beautiful that I couldn’t help but take a moment to appreciate the stunning view in front of me—this is awesome, it felt like something slot straight out of a painting.
Woooo, such a great article
This information is awesome slot
Great information and thanks toto
If you are a player looking to enhance your Guild Wars 2 experience, one of the most sought-after services is the ability to buy Gw2 Legendary Armor Envoy boosting. This service allows you to obtain high-end armor that is usually time-consuming and challenging to craft. By using boosting services, you can save countless hours of farming materials, completing difficult achievements, or grinding reputation points. It’s a great way for casual players or those short on time to catch up with friends in PvE or PvP content. Many players find that investing in boosting helps them enjoy the game without feeling overwhelmed.