The initial data corpus for this project is composed of twenty-five files, formatted using UTF-8 (8-bit Unicode) character encoding as both plain text and XHTML. These were produced using materials hosted by the Marxists Internet Archive, through a process of carefully cleaning the content via regular expressions. Extraneous presentational markup and line endings were removed, and replaced by semantic markup where applicable.
XHTML was selected because, as a markup language written according to the XML standard, it supports incorporating additional metadata. For this project we wanted to include information about the location where a document was originally written as well as the date, and this was accomplished using a set of elements defined by the Dublin Core Metadata Initiative. For example, Marx and Engel’s Manifesto of the Communist Party was created in Brussels, Belgium, in February of 1848, so the XTHML version contains the markup:
<meta name="DC.date" content="1848-02-21" /> <meta name="DC.coverage.x" scheme="Point" content="4.3333" /> <meta name="DC.coverage.y" scheme="Point" content="50.8333" />
Here the longitude and latitude are represented as decimal degree geographic coordinates, and this additional data can be used for incorporating maps and timelines. The original materials are provided through the public domain, and the prepared collection is publicly accessible at http://adiuva.me/marx/.
Because one of the project goals is to produce graphic visualizations, an early experiment plotted the top five words in each text:
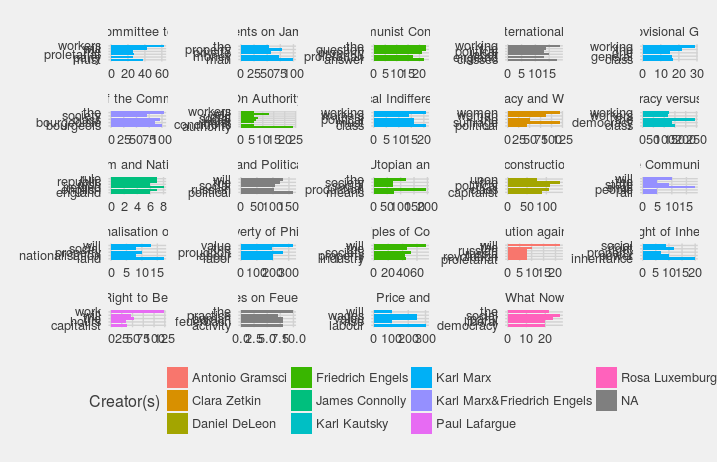
Although cluttered, this image illustrates the frequency in which these terms appear. There are a few ties in some of the counts, resulting in more than five terms in a few graphs. For example, In his essay On Authority Friedrich Engels used the terms “workers,” “upon,” and “conditions” six times each, resulting in a total of eight terms in the grouping. Each plot has different frequencies set, as they can vary considerably from one work to the next, most likely due to the different lengths of the texts themselves.
Below is an early attempt at generating an Alluvial Diagram:
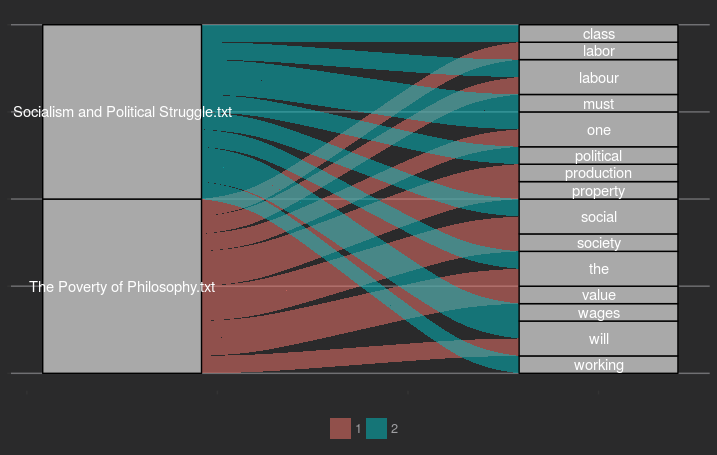
This was created with the R programming language topicmodel package (Grün and Hornik, 2011). The underlying method uses latent Dirichlet allocation to generate topics from a document term matrix, classifying each document as a mix of topics and each topic as a mix of words. Every term is connected with its originating document, and shared words, or groups of words, are illustrated by a connection. Interestingly, although documents may share some words they do not necessarily share a topic.
when i read this article, i felt something interesting, maybe i will share this to others too.