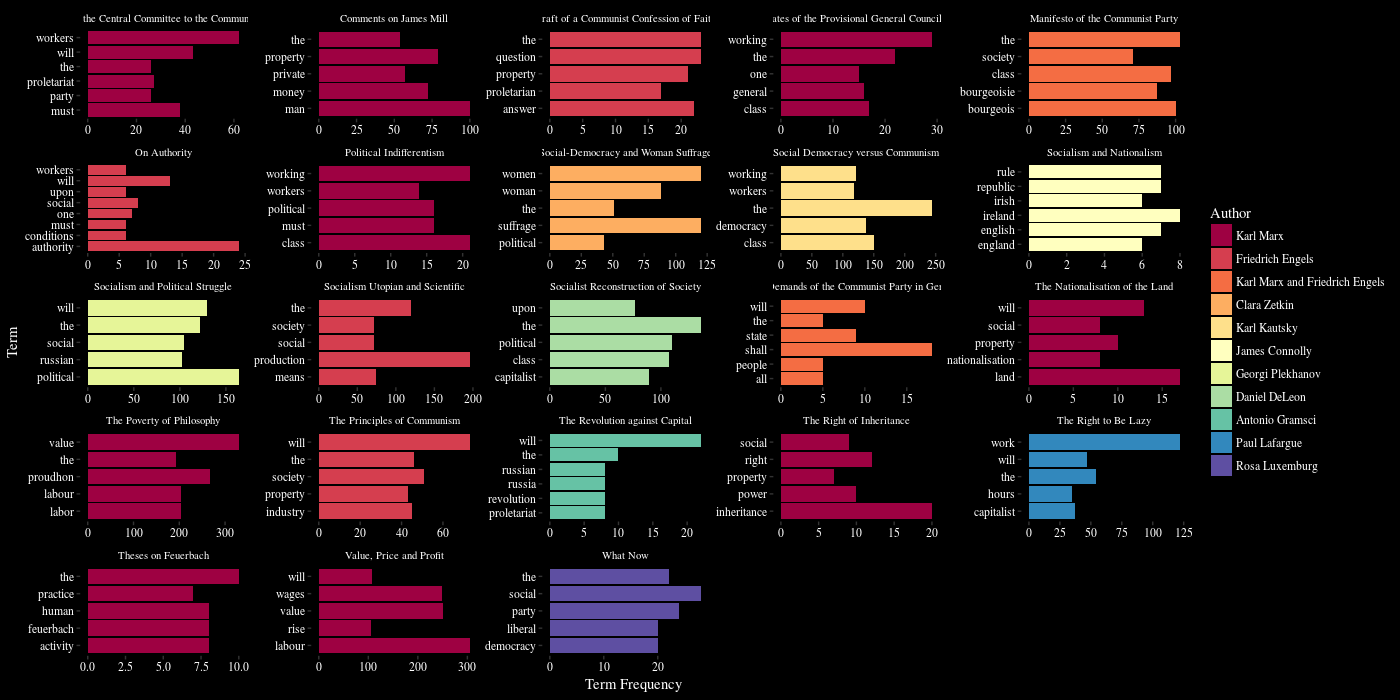
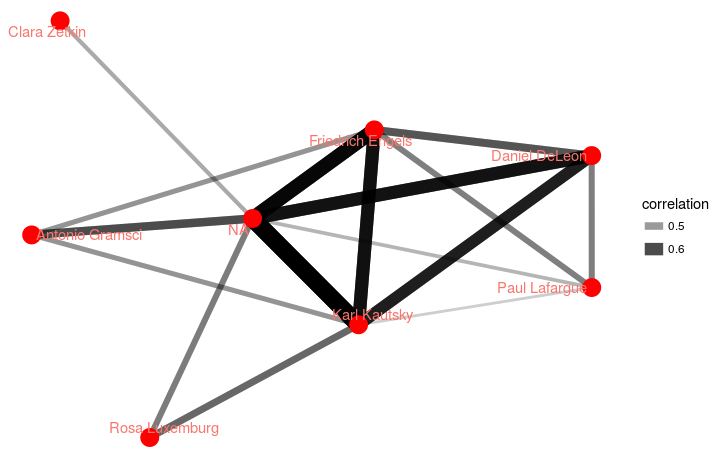
As part of our ongoing experiments in visualization, I recently rebuilt a personal website using Omeka (or more specifically what they’re now calling “Omeka Classic”), a lightweight web publishing platform for digital collections from George Mason University’s Roy Rosenzweig Center for History and New Media. Previous exposure suggested that, by itself, it could make a decent digital asset management add-on to an existing site due to its metadata support. In this instance I wanted to discover the benefits Omeka offers when treating our corpus of plain text files as an online collection.
As it happens, there are a number of very nice plugins extending the functionality of Omeka, and several are specifically designed for text analysis and visualization. With the file content attached as an item type metadata (in this case the textual component), I was able to use the Ngram plugin to analyze term frequency and plot it over time.