One of the initial project goals was to provide a means for examining the text using keywords, or more specifically a variation on the tools designed for “keywords in context” (KWIC). This technique involves generating a concordance, a list of the words used within a text along with those words immediately surrounding them, as a means for providing context. Traditionally, generating a concordance was a labor-intensive process reserved for only the most important books, often source texts that serve as the foundation for religion, such as the Judeo-Christian Bible.
As a linguistic tool, examining the collocation of terms and their respective uses across a corpus can provide valuable research insights, and with the advent of digital text analytics applications generating these annotated corpora became significantly faster and more accessible.
It was our hope that, when applied to our collection of Marxist writings, the results could also have pedagogical value: By searching for a keyword of personal interest, perhaps drawn from current events or an unrelated research interest, a scholar unfamiliar with Marxism could gain insight from how the terms were applied, resulting in something of a “Marxist perspective” on the topic.
Unfortunately the Open Source tools available to build a custom KWIC web application are somewhat limited. There are several desktop applications, such as AntConc and KHCoder, but the server-side applications appear to be both built primarily using Java and requiring significant customization. Although this doesn’t rule out building one, for a near-term solution we used the Voyant Tools, a collection of research applications developed to enhance humanities reading through lightweight text analytics, with particular emphasis on HTML documents. With our corpus available in valid XHTML, it was uploaded and examined using the Voyant “Contexts” tool.
The initial results were interesting. Contexts identified the top ten keywords (“class” being first), and generated concordances for them across the entire corpus.
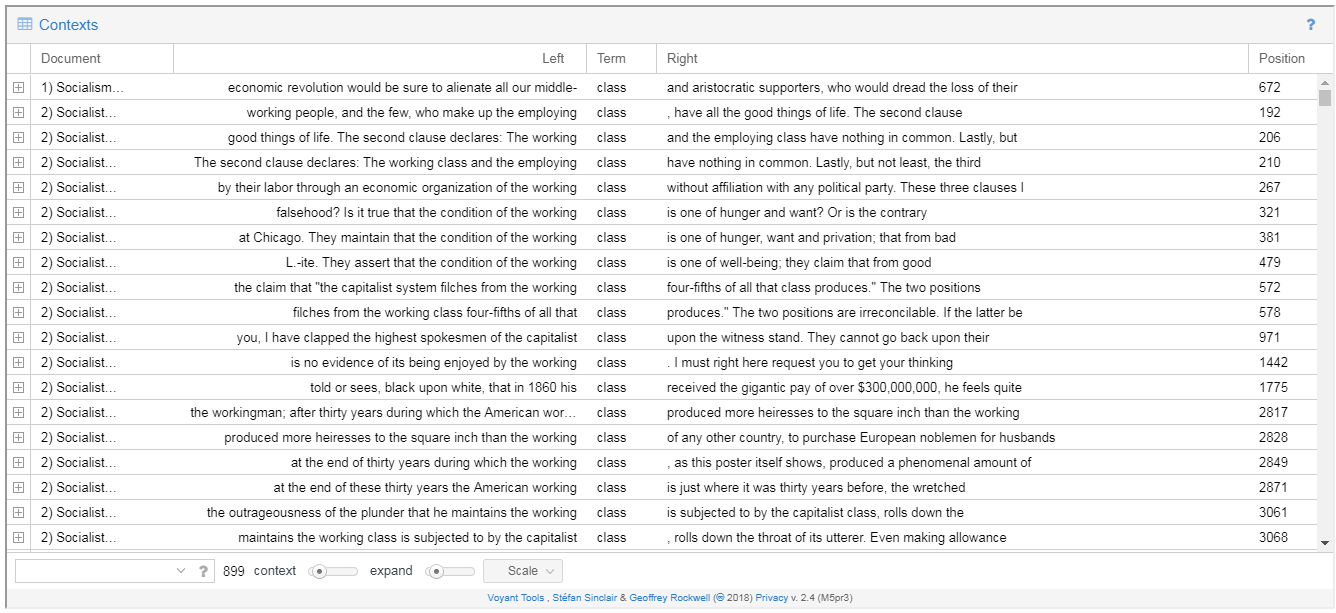
The selections are listed alphabetically by author, with the document title in the first column, and the selected keyword is displayed in the center. The “context” and “expand” sliders at the bottom of the screen increase the amount of text displayed on either side of the keyword, and using the “plus” icon to the left of the title reveals the expanded passage.
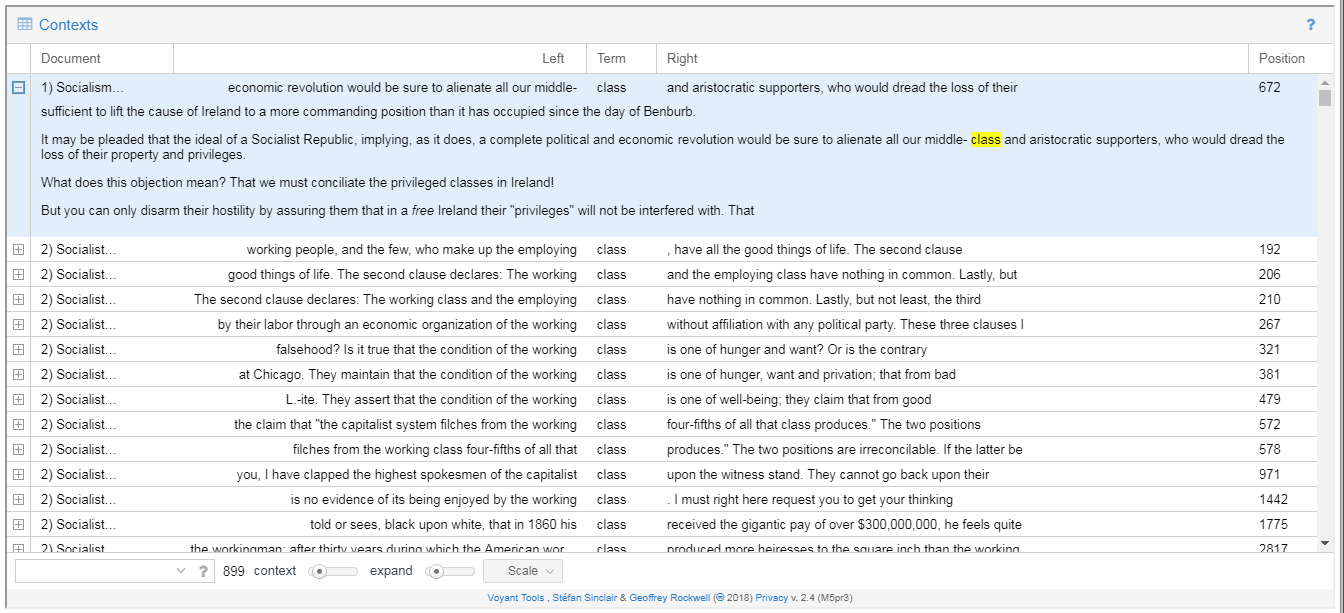
Particularly interesting are the results from a random keyword. Assuming it can be found, Contexts applies wildcard stemming, revealing unexpected instances. Consider the search for “fool” and its variants:
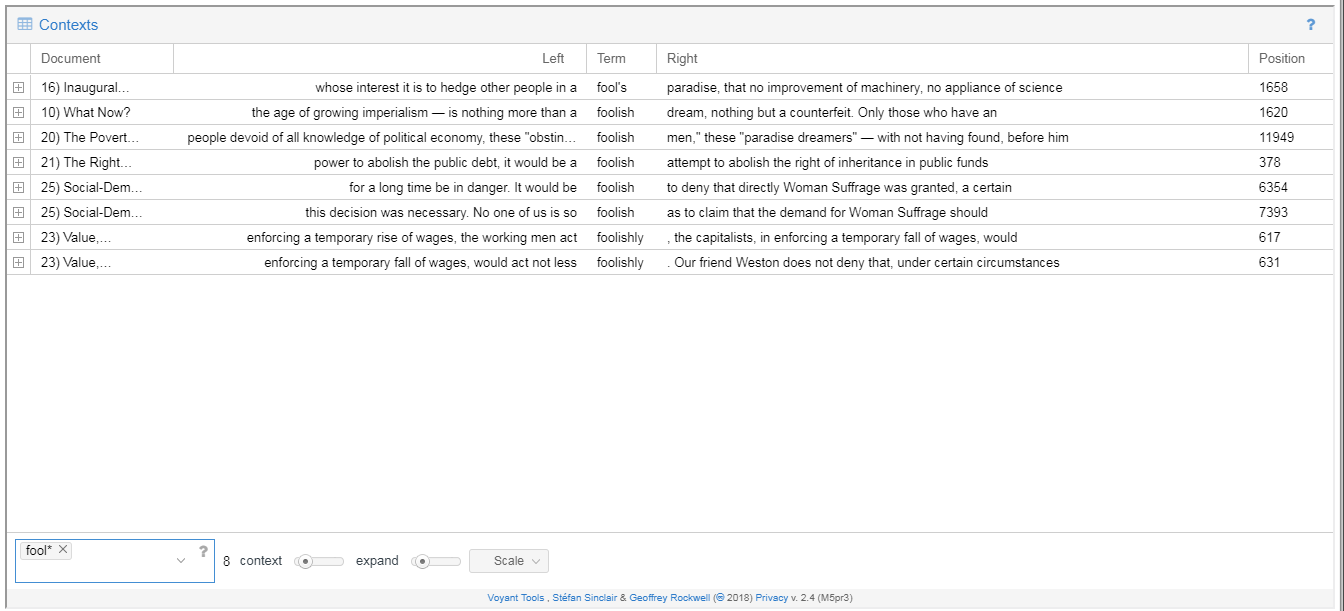
Applying a keyword relevant to a particular interest, such as use of the term “suffrage” is also revelatory:
Although it is possible to limit the results to specific texts, as a web application hosted on an external server the Voyant Contexts tool can be slow and prone to stalling, particularly when non-indexed keywords are searched. Adding or removing materials requires generating a new corpus, and there are limits placed on how many documents the service is willing to contain. As an open source project, however, it is possible to host a dedicated instance of the Voyant Tools. Should the project generate sufficient interest, such an approach is worthy of consideration.
In the meantime, access to the corpus via Contexts is available at http://adiuva.me/marx/contexts.html.
The idea of a concordance is a good one when it comes to a collection of works by someone like Marx. That’s a large undertaking that would require a more involved absorption of Marx’s works and their content than you may be able to tackle at this stage. As a first step toward providing more descrptive information about content, I would like to see a summary of sorts, 150 words or so, for each book in the current digital collection. Although I’m conversant with some of the main concepts of Marxism, my sporadic reading means I cannot recall which concept he addressed in which book. He repeated himself extensively, but it would be good to have a brief overview of each work so the reader has a contextual starting point for doing some keyword searching.
That’s an excellent idea — and in keeping with the nature of the project, ideally one that could be accomplished programmatically.
It might be useful to apply Topic Modeling, generating information that would fill a similar role to the summaries you describe. Not exactly a general description, but a “label” of the main themes, alongside a series of keyword “tags.” Definitely something to keep in mind for a future iteration.
Often, you wish to determine the context in which a given term is used. In this case, you can create and print a so-called KWIC (KeyWord In Context) listing.
Its a great idea to use keywords in the context including title, and heading. Create hyperlinks with follow or dofollow. Results will be on the top.
Topic modeling can generate “labels” or main themes for your content, along with relevant keywords. This could be a valuable tool for future iterations.
sangat bagus dan aku sangat tertarik akan hal tersebut, terima kasih telah memberikan informasi nya
Come Play Now And Get Big Jackpot At Bandar Togel
This content is very good, I am very interested, and here is my content
when i read this article, i felt something interesting, maybe i will share this to others too.
I was lucky to have found this on Google and it helped me to estimate my website, please see Google
Registration here is really fast and easy. No need to be complicated, you can immediately start exploring many exciting gacor slot games. The platform is also easy to navigate
The platform is truly a different experience. Everything feels smooth and responsive — from the moment you log in to the moment you start playing, everything runs smoothly. The design is user-friendly, the features are comprehensive, and the process is fast. But most importantly, I feel completely safe every time I access it. This combination of convenience and security is rare. It’s top-notch!
Wow, what a great articleThe explanation is complete but still easy to read. Kudos to the admin who can bring up issues like this in depth. I also happened to discuss something similar on the blog, so happy to get additional insight from here
The writing is really greatThe writing style is easy to follow and makes me want to read it until the end. This article is very relevant to the discussion that I am currently raising on the site, so it is perfect as an additional reference~Thank you
aku ingin memastikan bahwa seompong tidak ada disini.The writing is really greatThe writing style is easy to follow and makes me want to read it until the end. This article is very relevant to the discussion that I am currently raising on the site, so it is perfect as an additional reference~Thank you
The level of detail and attention to user experience is incredible. It’s rare to find a site that combines speed, functionality, and trust so seamlessly. A real
There’s a clear sense of professionalism here. Every interaction, every feature feels premium. It’s no doubt one of the most trusted platforms I’ve come across. bsdtogel in every way.
Agen Mesin Slot
TOTOCC
TOTOCC situs slot terbaik..
TOTOCC
Agen Mesin Slot
TOTOCC
what do you think about seompong terbaik dan terpercaya 2025 keren di totocc.
seompong at here, totocc no problem bro terbaik dan terpercaya 2025 ok banget lah.
seompong at here, wiro4d no problem bro terbaik dan terpercaya 2025 ok banget lah.
ini baru situs jelas di totocc. gas kan
bagusnya apa di totocc. boleh nih bos
baru terasa nyaman main di wiro4d. wirosableng ni bray
coba saja gak ada salahnya di totocc. sikat bos
masuk terus nih di totocc. sikat bos
terbaik dari semua yang terbaik di totocc. sikat bos
tahun 2025 ini meledak totocc. sikat bos
kemarin sudah rasakan dan nyaman di totocc. sikat bos
semuanya bahagia bermain di wiro4d. mampir sini ada seompong
Bagi yang belum coba Wiro4D, rugi banget! Pelayanan top markotop!
barusan ada update terbaru di totocc.
bermain di totocc enaknya minta ampun.
makan tidur santai main di totocc.
meskipun lelah, tetap semangat di totocc.
hajar saja, jangan kasi kendor di totocc.
yuk mainkan terus di semua permainan totocc.
tempat main yang seru dan terpercaya? Langsung aja ke TotoCC. gas saja
Bergabung di TotoCC yuk! Mainnya seru,melimpah. maju terus
wiro4d itu tempatnya hoki dan keberuntungan — buruan daftar. simak
Mabar di TotoCC itu membuat hari makin semangat. akun gacor
totocc tempatnya para jomblo untuk berkumpul. bersama indah
Bonus banyak, game semua ada, dan layanan top? Cuma di totocc. masuk nih ye
totocc selalu memberikan kejutan! Daftar dan dapatkan hokimu. ompong nih
suruh teman kamu main di totocc. seompong oke
simpan saja link di totocc.
mari bermain bersama sama di totocc.
ini barusan wiro4d. lanjutkan terus jangan menyerah
kumpul bareng main di totocc.
bermain di totocc itu cuan terus tanpa henti.
seompong ini bagus kalau di teruskan di totocc.
harus bisa nih , biar kencang terus di totocc.
Lagi cari tempat main aman dan gacor? Langsung aja ke wiro4d!
Gak nyesel join di TOTOCC, withdraw super cepat dan respons adminnya mantap!
Coba deh sekali main di TOTOCC, dijamin ketagihan!
Daftar gampang, bonus melimpah, cuma di wiro4d!
Mau cari hoki hari ini? Main aja di TOTOCC!
Gak cuma hoki, tapi juga pasti dibayar! Terpercaya banget nih TOTOCC
Main bareng temen makin seru di TOTOCC. Ada banyak bonus referral loh!
Gacor parah! Baru main langsung WD di TOTOCC!
Banyak event seru tiap minggu di TOTOCC, buruan gabung!
Daftar wiro4d gak pake ribet, langsung main dan tarik kemenanganmu!
Baru daftar udah dapet bonus? Hanya di wiro4d!
Jackpot gede gak cuma mimpi kalau main di wiro4d
Bonus harian bikin makin betah di wiro4d!
Dapet bonus deposit sampe ratusan ribu di wiro4d!
Jackpot jatuh tiap hari! Mainnya di mana lagi kalau bukan di wiro4d
Udah coba banyak tempat, tapi paling nyaman di wiro4d. Aman dan terpercaya!
Proses withdraw cepet banget, gak pake ribet! Thank you wiro4d
CS-nya fast respon banget. Baru chat, langsung dibantu. Mantap wiro4d
Gak takut kena tipu, karena wiro4d 100% aman dan legal!
Udah langganan lama di wiro4d, gak pernah kecewa sama pelayanan mereka!
Game-nya lengkap banget! Dari slot sampai live casino ada semua di wiro4d
Gak bikin bosen, soalnya wiro4d selalu update game baru
Grafik game-nya keren, serasa main di kasino beneran!
Kalah menang tetap seru kalau main di wiro4d, karena dapet cashback!
Bosan main di tempat lain? Pindah ke wiro4d, dijamin betah!
Kalo kamu belum coba wiro4d, kamu belum tahu serunya main game yang beneran gacor!
Mulai dari iseng, eh malah cuan beneran. Thank you wiro4d
Weekend paling asyik? Rebahan sambil gacor di wiro4d
Ssttt… tempat jackpot tersembunyi itu namanya wiro4d
Yang penting main di tempat yang bener, kayak wiro4d. Baru berasa cuannya!
Ada yang udah coba wiro4d? Gimana, gacor gak?
Gue sih udah di wiro4d, kalian kapan?
Siapa yang udah WD hari ini dari wiro4d? Bagi tips dong!
Lagi hoki banget nih di wiro4d! Kalian udah coba belum?
Ada bonus apa hari ini di wiro4d ya? Gak sabar ngeclaim!
Lagi ada promo gila di wiro4d! Buruan join sebelum kehabisan!
Event spin gratis bikin makin seru! Cuma di wiro4d
Dapet THR dari wiro4d tuh rasanya beda banget!
Baru tahu soal TOTOCC, ternyata layanannya oke banget.
Siapa di sini yang udah coba TOTOCC. Worth it nggak?
WIRO4D bikin urusan jadi lebih mudah. Keren sih.
Aku pikir biasa aja, ternyata TOTOCC profesional banget.
Layanan dari TOTOCC emang beda, detail dan niat.
Gak nyangka TOTOCC bisa secepat ini responnya. Mantap.
TOTOCC itu jawaban dari semua kebingungan saya selama ini.
Dikasih tahu temen tentang TOTOCC, eh malah ketagihan pake terus.
Kalau belum cobain TOTOCC, belum lengkap sih rasanya.
TOTOCC tuh definisi simple tapi powerful.
Wiro4D emang tempat gacor buat main, WD ngebut tanpa drama
Udah coba banyak situs, tapi TOTOCC paling stabil & terpercaya
Gak nyesel gabung di TOTOCC, bonusnya banyak banget
Baru join TOTOCC, langsung hoki JP perdana! Mantap!
Main di TOTOCC, saldo cepet naik. Gaskeun bosku!
Cuma di TOTOCC yang kasih bonus harian tanpa syarat ribet!
Promo cashback TOTOCC bikin main makin aman, kalah pun dapet balik!
Top up di TOTOCC selalu ada bonus tambahan. Gila sih!
TOTOCC bikin hari-hari lebih semangat dengan promo gilanya!
CS Wiro4D fast response banget, jam berapa pun dilayani!
Tampilan website Wiro4D user-friendly, enak dipakai!
Deposit & WD di Wiro4D super cepat, gak pake nunggu lama!
Game lengkap dari slot, casino, togel, semua ada di Wiro4D!
Paling nyaman main di Wiro4D, gak lemot & jarang error!
Gak usah ragu, Wiro4D udah terbukti terpercaya dari dulu!
Amanin akun kamu di Wiro4D, datanya dijaga ketat!
This platform offers a completely unique experience. From logging in to playing, everything runs without a hitch. The interface is simple to use, the features cover everything I need, and the speed is impressive. What stands out most is the sense of safety I get each time I use it. That mix of ease and trust is hard to come by. This one truly delivers.
Sedap banget main di TOTOCC.
sensasi berbedan bermain dengan teman di TOTOCC.
kalau ini bukan sableng di WIRO4D.
semangat dan akhirnya membuahkan hasil di TOTOCC.
kembali bersinar dan berjaya di TOTOCC.
apapun yang terjadi , semua rasanya tetap TOTOCC.
pertanyaan apa situs terbaik, ya TOTOCC.
mau menang dan gak mau kalah , ya di TOTOCC.
kekuatan penuh untuk meningkatkan kejayaan TOTOCC.
Tempat main slot yang aman, nyaman dan terpercaya cuma Empire88
unsurtoto Smooth, intuitive, and secure—that’s what makes a great betting site.
unsurtoto Security and reliability outweigh temporary bonuses every time.
bandar togel This is cool, keep writing because this blog doesn’t get boring to read
agen togel This page offers an excellent and well-structured overview of the subject. The combination of reliable data and thoughtful commentary makes it very helpful for readers like me who want to stay informed. Please continue providing such high-quality resources!
coktogel I like the layout of the blog that you created, it makes me more creative.
Thanks for this good article, by the way my name is 19DEWA
I like the blog you created, with neat writing and important content, it gives me lots of new references. don’t forget to stop by my site, I hope your visit is worthwhile coktogel
This is very interesting, and there are many things we can learn here, hopefully it will be better and can provide many people with important lessons. Don’t forget to stop by my blog, thank you. coktogel
The content is informative and well written, allowing readers to follow complicated discussions smoothly while gaining practical knowledge for real world application.
A strong article with clear explanations and a smooth reading flow. It’s easy to stay engaged.
The flow of the article encourages sustained attention, as each point leads naturally into the next without abrupt transitions.
This impressive scholarly-style composition delivers clarity by integrating structured arguments, analytical precision, refined expression, and engaging explanation.
This content offers dependable insights through organized writing and accurate explanations for readers.
Clear organization and meaningful analysis support learning while keeping the content engaging and easy to follow.
Informative tone and elegant delivery help convey ideas clearly while reinforcing credibility and reader trust.
I appreciate this well written post because it delivers valuable knowledge clearly, using structured organization, simple language, and engaging style that makes the content trustworthy, accessible, and highly useful for diverse audiences.
This content feels well prepared, combining logical sequencing with clear language that supports understanding from the first sentence until the conclusion.
I value this post because it communicates ideas efficiently, avoids unnecessary repetition, and focuses on delivering information readers can realistically use and trust.
Your comment adds value by strengthening informational depth, supporting accuracy, encouraging thoughtful reading, and assisting readers in navigating complex topics.
Thank you for adding meaningful input, it supports informed dialogue, builds confidence, enhances comprehension, and benefits readers seeking accurate knowledge.
Your comment is valued for adding depth, strengthening confidence, encouraging curiosity, and helping readers discover meaningful information aligned with this topic.
Thank you for your contribution, it enhances conversation quality, supports reliability, encourages thoughtful reading, and benefits readers seeking accurate understanding.
I appreciate how this work supports understanding through concise explanations and a thoughtful informational approach.
This content improves comprehension by organizing explanations in a logical and reader friendly manner online.
The content builds comprehension by reinforcing ideas through clear and consistent explanation online.
I appreciate content that remains clear practical structured accessible wording friendly communication balanced relevance clarity usefulness accuracy engagement.
This post delivers informative explanations that help readers understand the topic clearly and remain interested throughout the discussion.
Readers benefit when appreciation acknowledges meaningful contribution and thoughtful presentation rather than surface level acknowledgment alone.
Thoughtful appreciation like this supports constructive discourse by rewarding communication that prioritizes comprehension, relevance, and well structured presentation across digital platforms.
Praise recognizes structured narration informative clarity engaging presentation accessible language thoughtful intent reader confidence.
Readers appreciate storytelling about remote destinations emphasizing natural beauty, respectful observation, cultural humility, and thoughtful interaction with local traditions.
I admire the quality and usefulness of this article. The writing is clear, and the insights are presented thoughtfully. Thank you for consistently sharing knowledge that helps readers learn and grow effectively.
learn more here spindashgalore.com
B0878
T0812
LINK LOGIN T0812 Login
great slot
B0878
B0878 Daftar
This article is so amazing slot
Discovering insightful publication affirmed credibility via thoughtful sequencing ethical presentation disciplined clarity originality balance professionalism reliability relevance engagement.
Fantastic resource explaining concepts effectively combining detail brevity accessibility friendliness relevance encouragement inspiration positivity growth learning clarity structure quality usefulness professionalism trust value contribution appreciation
Insightful commentary guiding improvement reinforcing knowledge relevance usefulness gratitude learning insight professionalism trust quality effort dedication value respect authority credibility clarity