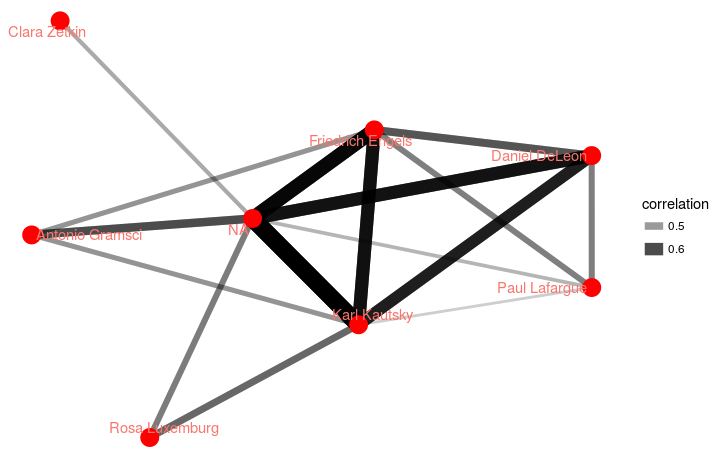
After experimenting with the Interrogating Marxism apps, I came up with some intriguing questions:
- It is clearly apparent on the Neatline map at http://adiuva.me/neatline/show/interrogating-marxism that most of the red spots that represent the Marxist works in the database for this website are in countries like Britain, France, Germany, and so on. In other words, it seems that a lot of the works were written in Western Europe. Is this true of other Marxist works? And then it is so interesting that a lot of the former Socialist countries were in Eastern Europe, rather than the west, where a lot of our representative Marxist works were written. Why is that? And what about the text from United States? Where is it located in the U.S., and what happened there? Why was it written there? Is there strong Marxist influence at that place today?
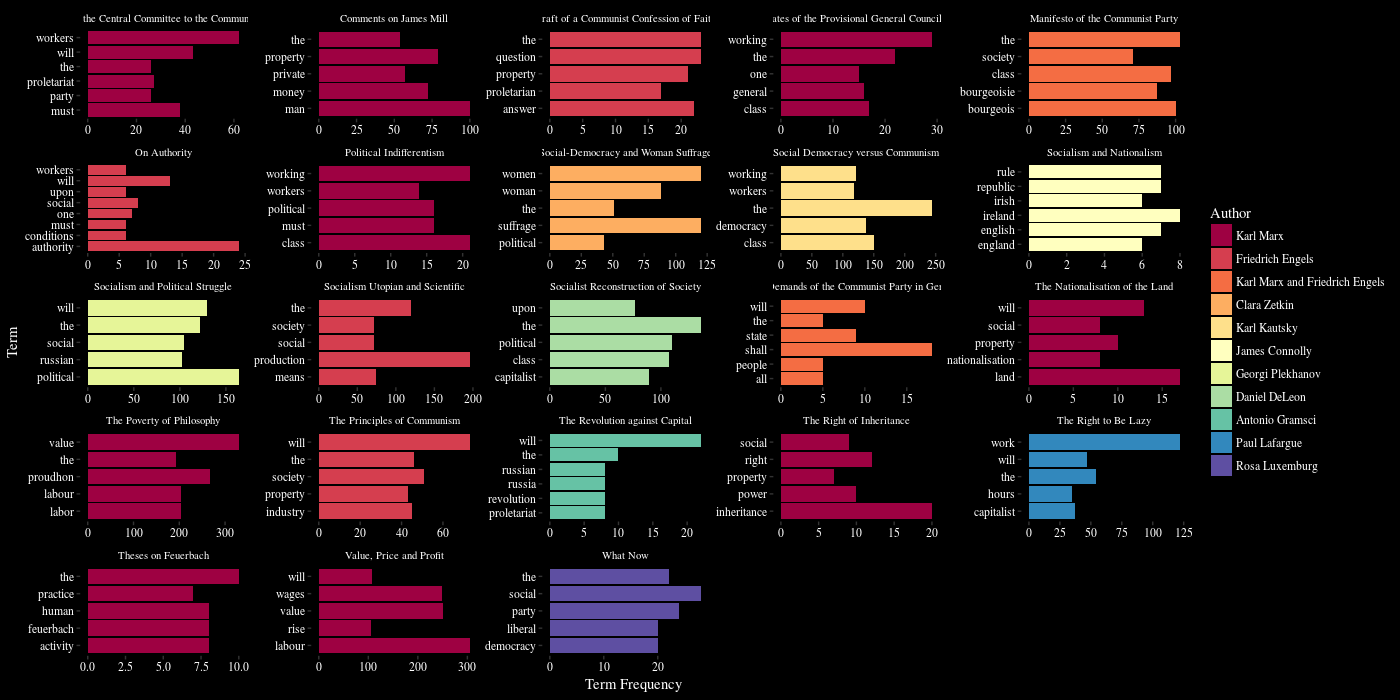
- In the Ngram frequency results, if we skip all the “stop words” (such as “is, they, and” and so on), the word bourgeois ranks quite high on the list, with a frequency of 331 and a relative frequency of 0.132503%. I found myself quite curious: Why is this word getting so much attention from the Marxist authors? Continue reading